Version updates
| Resource | Previous version | New Version |
|---|
| nsx-default-stack | 2021.9.0 | 2022.8.4 |
| Expanders | 5.1.0 | 5.9.9 |
| base-components | 2021.3.1 | 2022.7.1 |
| web-styles | 2021.1.0 | 2022.4.1 |
Breaking Changes
- The
net.palver.util.Options.Option class no longer accepts null values. Option types exist to represent nullable
values in a more typesafe way as either Some {value} or None. Some null breaks this contract.
If you need to convert a value that can be null, use the Options.notNull(V) method
- Removed name field from ProjectionPojoExpander with option
nameNotWanted.
The name field was still being set for DataElements with the nameNotWanted option, which was redundant.
To revert this behaviour, use legacy.nameNotWanted.pojoName.
- Deprecated JndiProperties and removed its behavior as it pertains only to obsoleted external RMI invocation
- Deprecated net.democritus.mapping.Base64 in favor of java.util.Base64
- Removed classes: FileInserter, ReportFile, SimpleHtmlFormat (for removed ReportExpander)
New Features
OpenID Connect
The account component now supports OpenID Connect, which allows you to authenticate users using any provider that
follows the standard.
See here for more detailed information.
This page describes the setup and solutions for Google Cloud Platform, Microsoft Azure, Keycloak and Auth0.
XML representation of the Model
The format described here is the way the µRadiant exports the model files and how
prime-core writes the files when writing model files programmatically. We will release a tool to automatically convert
a model using maven in the near future.
Model files described in the old format are still compatible and can be used to expand
with the newest version of the stack.
There have been a number of improvements to make the model XML files more readable and concise.
First, several irrelevant fields have been removed from the model. In addition, fields that are empty will not be
exported.
You can see the effect in the Component XML, where only the relevant information remains:
<component name="account">
<version>1.0</version>
<fullName>BASE:account</fullName>
<businessOwner name="NSX"/>
<modelOwner name="NSX"/>
<firstAnalyst name="Paul"/>
<modelRepository name="BaseComponents"/>
<customRepository name="BaseComponents"/>
<description/>
<mainScreen/>
<componentDependencies>
<componentDependency name="account:utils">
<dependsOn name="utils" version="1.0"/>
<isManyToMany value="false"/>
</componentDependency>
</componentDependencies>
<componentOptions/>
</component>
<component name="account">
<version>1.0</version>
<fullName>BASE:account</fullName>
<componentDependencies>
<componentDependency name="account:utils">
<dependsOn name="utils"/>
<isManyToMany>false</isManyToMany>
</componentDependency>
</componentDependencies>
</component>
You may also notice that the boolean values are no longer represented as attributes, to be more in line with other
values:
<field name="name">
<fieldType>VALUE_FIELD</fieldType>
<description/>
<isInfoField value="true"/>
<isListField undefined="true"/>
<valueField name="ValueField:Account_name">
<valueFieldType component="" name="String"/>
</valueField>
</field>
<field name="name">
<fieldType>VALUE_FIELD</fieldType>
<isInfoField>true</isInfoField>
<isListField>false</isListField>
<valueField>
<valueFieldType component="" name="String"/>
</valueField>
</field>
Next, the options follow a more compact notation. Options are always key-value pairs, which allows us to use a more
compact notation:
<componentOptions>
<componentOption name="account:hasDataBaseSchema">
<value>ACCOUNT</value>
<componentOptionType name="hasDataBaseSchema"/>
</componentOption>
<componentOption name="account:isBaseComponent">
<value/>
<componentOptionType name="isBaseComponent"/>
</componentOption>
<componentOption name="account:baseComponents.isAccount">
<value/>
<componentOptionType name="baseComponents.isAccount"/>
</componentOption>
<componentOption name="account:configuration.properties">
<value/>
<componentOptionType name="configuration.properties"/>
</componentOption>
</componentOptions>
<options>
<hasDataBaseSchema>ACCOUNT</hasDataBaseSchema>
<isBaseComponent/>
<baseComponents.isAccount/>
<configuration.properties/>
</options>
Not coincidentally, this arrives together with a unified representation of option-types in the model.
If you are interested in representing the option types of your expanders, optionally with some value constraints,
read this.
Target Element of TaskElement
Historically, the target element of a TaskElement was represented by the targetClass field, which contained the
qualified java class name of the projection of the target element:
<targetClass>net.demo.PersonDetails</targetClass>
It was later replaced with a more correct link to the DataElement:
<targetElement component="registration" name="Person"/>
The targetClass field, however, allowed 2 additional use-cases:
- To use an alternative projection in the task
- To create a task that takes a custom class as input
To support these cases, the following options have been introduced:
target.element.projection: Changes the projection used from Details to the provided valuetarget.class.custom: Overrides the parameter type with the value (takes a fully qualified name)
The custom input class does not work in workflows or any other integration of the TaskElement in generated code.
Model Validations
The model validations are a set of rules which can be used to generate reports for application models and generate
a report detailing any rule violations.
The model validations were already available in some respect, but difficulty to use.
It is now possible to run the validations as a maven goal using the expanders-maven-plugin.
In addition to this, the rules are now packaged in expansion-resources, which makes it easier to distribute them.
It also makes it possible for teams to develop their own set of rules and include them in the report.
Check out the Model Validations tools page to get started.
If you are interested in creating your own rules, go to this page.
Better traceability of errors during model loading
Some exceptions during the model loading lacked crucial information to trace back the exception to it's cause.
This has been improved by keeping track of a model execution context. When an
exception is thrown, the model execution context will be added to the exception message:
If you are interested in how models are loaded, you can find more information on
this here.
net.democritus.elements.ElementNotFoundException: Cannot find Field(registration::Person::Status)
at FlowElementTreeToComposite.getStatusField (statusField=Status, targetElement=<DataElement registration::Person>)
at FlowElementTreeToComposite.mapTree (tree=<FlowElement registration::PersonFlow>)
at ComponentTreeToComposite.mapFlowElement (flowElement=<FlowElement registration::PersonFlow>)
at ComponentTreeToComposite.mapTree (tree=<Component registration>)
at ModuleCompositeModelLoader.loadModules (moduleType=<ModuleType elements::JeeComponent>)
at ExpansionCompositeModelConverter.convert (program=<Application demo::1.0.0>, programType=<ProgramType elements::JeeApplication>)
at ModelLoader.performStep (step=ConvertModelStep)
at ModelLoader.loadModel (expansionSettings=F:\NSF\workspace\demo\conf\expansionSettings.xml)
This reveals that the issue occurred:
- during the ConvertModelStep, (Converts Tree representation to interconnected Composite representation. This step
will
look up every reference and replace it with an object reference. Hence, missing faulty element reference will usually
break here.)
- while converting the registration component,
- specifically when converting the PersonFlow FlowElement,
- when the FlowElementTreeToComposite class tried to resolve the statusField
With this information, we can conclude that for some reason the field status does not exist on the target
DataElement Person. Looking at the corresponding DataElement XML file will then probably reveal that we forgot to add
the field.
ContextRetriever in Control Layer
For each request, the Context object is now provided by the ContextRetriever class.
This class allows you to add additional context objects to the context, which will be available in each layer through
the ParameterContext.
public class ContextRetriever {
public static Context getContext() {
Map<String, Object> session = ActionContext.getContext().getSession();
Context context = (Context) session.get("context");
if (context == null) {
context = Context.emptyContext();
}
if (context.getContext(UserContext.class).isEmpty()) {
}
return context;
}
}
An example of this is a TranslationContext. In this application, admin user can insert translations
for different languages into the database for a number of values. When a user retrieves the data,
the TranslationContext
provides the correct language for each user.
The TranslationContext is assigned in the ContextRetriever based on information in the session.
context=context.extend(TranslationContext.getTranslationContext(context,session));
Note that the Context object is immutable and needs to be reassigned after extending it.
Another example is a TenantContext in an application where all data is linked to a tenant.
Users have a tenant assigned to them and when data is retrieved, it is filtered based on the tenant provided by
the TenantContext.
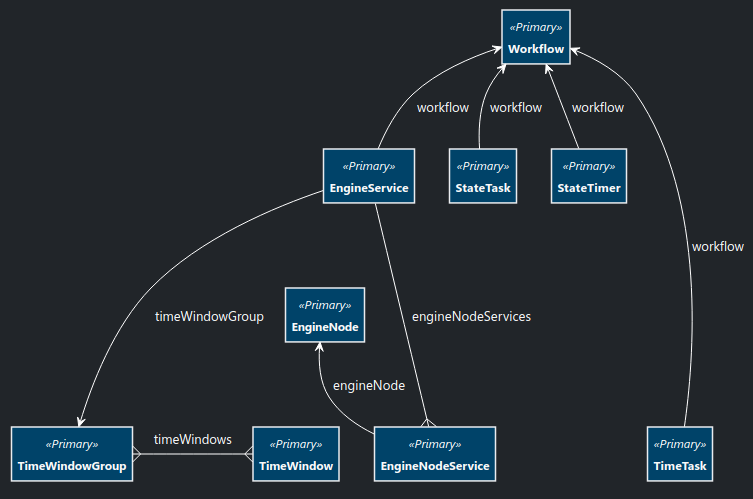
Workflow
The EngineService table has 2 new buttons:
- A 'Refresh' button to force a timer reset when settings have changed. This currently on works for single-node
applications.
- A 'Run Now' button to run the EngineService a single time.
To test the recovery mechanism, it is now possible to trigger the recovery with a http call to
the workflow/workflow-recover-json endpoint.
Provide the workflow reference as a parameter,
e.g. workflow/workflow-recover-json?workflow.name=MessageProcessorFlow
There are also a number of performance improvements, which are listed below.
NG Knockout UI
There are some small improvements in the UI to help with customizations:
- Use the applicationInstance/component/data option
cruds.table.csvExportButton to add a button to the
DataElement table which export instances as CSV, taking into account the selected finder.
- Added Data Option
view.buttons.commands, which adds buttons to NG pages to open command forms.
Primarily useful for prototyping and quickly testing new DataCommand features
- Added
command-button-builder to add buttons to execute commands in various ways
- Added optional parameters
searchMethod and details to data-download-action.ts to provide search
parameters when exporting data.
- Added option
size to popup, which can be set to large to make the popup bigger.
Second level caching in Hibernate 5
Add the option persistence.secondLevelCache to a DataElement to enable second level cache. Currently only available
for Hibernate 5 and is activated with SearchDetails.setAllowCaching(true).
Read more about it here
Component Application Settings
It might be relevant to have a properties file in your application server to configure properties of your application.
In this case, you can add the option configuration.properties to one or more of your components. This will generate
a <component>ApplicationSettings class, which reads <component>.ns.properties from the classpath and exposes the
properties defined in the file.
This can be a good alternative to keeping configurable properties in the ParamTargetValue table. Especially in case of
security.
This option is already used in account, to allow configuration of the authentication and authorization mechanics.
DetailsWithoutRefs projection
Fetching the details projection can at times be too resource-intensive.
This is caused by the resolution of DataRefs. Each LinkField requires an additional lookup to resolve the information
for the DataRef, e.g. name.
For remedy this, the option projection.detailsWithoutRefs has been implemented.
By adding this option to a DataElement, a detailsWithoutRefs projection will be generated.
It contains the same fields as the details projection, but the linkFields are only represented as ids.
It can be useful to use this projection as target projection for a task. Or when retrieving a large amount of instances
in a find() operation.
Custom Anchors
There are some new custom anchors in the expanders:
- Several custom anchors have been added to methods generated by the Claims feature.
- Anchors have been added to FindAction in the Control Layer
- Added
fetch-after-create-queries anchors to FinderBean.fetchData().
- Moved the
getData-strategy anchors in the Cruds classes to a separate method, so that the getData-after
anchors are reached in case of a defined strategy.
Miscellaneous
Expansion
- Add the expansion option
expansion.failFast to your expansionSettings to fail at the first error.
- Add the expansion option
expanders.traceFeatures to enable feature tracing. Features tracing adds comments around
each inserted feature, which allows you to trace the origins of inserted code in the generated artifacts.
- Add option
harvest.skip to a Component to skip harvest for that component. (primarily useful
for model resources)
Cleanup
- Made
Cruds.getName() opt-in. Add transient.cruds.useGetName to add getName() to the Cruds classes.
Control Layer
- Enable
findAll to be used as searchMethod on the find-json struts endpoint
Finders
- Added support for finders with
in operator in combination with linkFields
Data Import/Export
- It was no longer possible to expand
export() and importFile() pipelines without the use of the includeCsvImport
and includeCsvExport options. This functionality is now available separately with the io.import and io.export
options for the DataElement.
- Add the application option
csv.import.merge, which changes the CSV import so that the imported fields
are merged into the existing data, as opposed to the original implementation, which overwrites all fields.
Bug Fixes
Expanders
- Fixed implicit name field not being initialized correctly
- Adding property
tomee.jpa.factory.lazy=true to persistence.xml when expanding for TomEE with Hibernate 5, to avoid
CDI loading issues. This is advised by Apache in
the TomEE documentation.
- Added InterruptRecoverer error handling
- Fix status capitalization in FlowStateTransitioner
- Fixed workflow claiming not working with
Se finders
- Fixed recovery failing because recovered instances were not claimed
- Expose messages from CommandResult
- Fixed Context not being passed by StateTransitioner, causing
compareAndSet() to fail if claims are used
- Added
checkClaims() to compareAndSet() method for claimable DataElements
- Fixed InterruptRecovererExpander duplicating
_FindByNotClaimed postfix if finder with postfix is not present in the
model
- Projector class did not add imports for types of local calculated fields.
- Fixed artifactLabel not being included in the application root pom
- Fixed FinderBean not using
{DataElement}Data.ENTITY_NAME and not applying jpa.entity.name.format option
- Fixed some copying steps (ext, harvest) not following active layer configuration (copying no{X}Layer files)
- Fixed
getStatus(), getStatusAsEnum() return type in case of noDataLayer
- Fixed
compareAndSetStatus() method in case of noDataLayer
- Hide tabs in waterfall setup for elements to which the users does not have view access
- Fixed expansion option
hideAnchors failing on .properties expanders
before-harvest and after-harvest are now correctly ignored for base-components. This prevents issues with harvest
files in base-components being cleaned during harvest.- Fixed ext directories for some layerImplementations not being generated because of missing variables when resolving
the conditions
Base-Components
- Removed start/stop engine buttons from workflow page, since they are automatically managed by the
EngineStarterBean
- Fixed automatic timer reset on timeout when settings are changed
- Fix incorrect timewindow validation in last minute of window
- Added error log when recovery state transitioning failed
Web-Styles
- access-rights.js: Update
approved variable before triggering granted
- Fixed loading for observableInstanceBuilder.js when minified
- Fixed tabs to always select the first tab on visibility changes until the user interacts with the tabs.
From then on, the selected tab is preferred.
- Fixed nullable DateTime input field
- Fixed loading for nsx-knockout-utils.js and nsx-interaction-model.js
- Change
nsx-navbar-fixed.css to fix issues with responsiveness
- Fix several require statements in old js files
- Use
nsx-navbar-static.css by default, since it is less buggy. (There is a patch
option webstyles.patch.navbar-fixed to revert this)
- Only load instances when tab in waterfall is visible, and hence a parent element is selected, to reduce page
load.
- Fixed missing oxide skin for tinymce
- Fix to size bottom of big dialogs properly
Run-time
- Made ClaimId serializable
- Added error log when recovery state transitioning failed
- Fixed Result class returning a null value on error. Instead, it now throws an exception if the getValue() is called on an error result. Implementations should always check the isError() or isSuccess() method first.
- Changed Context.getContext() typing to allow parameterized context groups
Workflow
- Workflow runtime configuration is now cached to reduce the number of database queries
- The
detailsWithoutRefs projection is used for several elements in workflow orchestration to reduce the number of
database queries
- Optimized
getParamTargetValue() with skipCount
- Increased recovery claim timeout to 5 minutes
- Updating EngineNodeService with projection to reduce database queries
- Optimized database query used to update engineService.lastRunAt
- Ignore collector from EngineService
UI
- Render waterfall tab only once an instance is selected